
สรุปหนังสือ Naked Statistics สถิติฉบับเซ็กซี่ หนังสือที่จะทำให้คุณเข้าใจเรื่องสถิติมากขึ้น ด้วยภาษาที่ไม่ยากเกินไป และยิ่งใครทำงานที่เกี่ยวกับ Data โดยเฉพาะ Data-Driven Marketing แนะนำเลยว่ายิ่งควรต้องอ่านหนังสือเล่มนี้ครับ
เพราะ Statistics หรือสถิติ คือเครื่องมือที่ช่วยให้เราทำงานกับดาต้าง่ายขึ้น ไม่ว่าจะการหาค่าเฉลี่ย Average ยอดขายของลูกค้าทั้งหมด เพื่อจะได้นำไปกำหนดกลยุทธ์ Promotion Campaign โปรโมชั่นส่วนลดว่าควรลดเท่าไหร่จึงจะสร้างยอดขายได้มากขึ้น ไม่ใช่ลดแล้วทำให้ขายได้ลดลง
นักการตลาดวันนี้ต้องเข้าใจความต่างระหว่างค่า Mean Median หรือ Mode เพราะหลายครั้งเราคุ้นแต่กับคำว่าค่าเฉลี่ย ซึ่งในความเป็นจริงแล้วค่าเฉลี่ยอาจเบี้ยวผิดเพี้ยนจากค่าความเป็นจริงส่วนใหญ่มากเกินไปก็ได้
คิดถึงภาพในร้านอาหารแห่งหนึ่ง มีลูกค้า 9 คน แต่ละคนสั่งอาหารรวมเป็นเงินคนละ 300 บาท เมื่อนำมาหาค่าเฉลี่ย Average ก็จะได้ 300 บาท ซึ่งดูเป็นค่าที่จริงที่สุด แต่พอมีคนที่ 10 เดินเข้ามา คนนี้สั่งอาหารรวมเป็นเงิน 30,000 บาท เพราะพี่แก่สั่งแบบสามล้อถูกหวย สั่งแบบห่อกลับบ้านไปเลี้ยงคนทั้งตำบล
ทีนี้ เมื่อนำยอดการสั่งของลูกค้าทุกคนมารวมกันแล้วหารเท่า เท่ากับว่าจากค่าเฉลี่ยคนละ 300 บาท ที่เป็นยอดซื้อของคนส่วนใหญ่ เมื่อรวมคนที่ 10 ที่สั่ง 30,000 บาทเข้าไป กลายเป็นยอดรวมของลูกค้า 10 คนเท่ากับ 57,000 บาท
พอเอามา 10 มาหาร เท่ากับว่าค่าเฉลี่ยของแต่ละคนคือ 57,000 บาท
พอเห็นภาพใช่ไหมครับ ว่าเหตุใดเราถึงไม่ควรใช้ค่าเฉลี่ยโดยไม่ตั้งคำถาม ซึ่งในกรณีแบบนี้เราควรขยับมาใช้ค่า Median หรือค่าที่อยู่ตรงกลางของจำนวนทั้งหมดนี้ ซึ่งก็ยังคงเป็น 300 ซึ่งดูแล้วใกล้เคียงความจริงมากที่สุด
แต่ในความเป็นจริงของการทำดาต้า ในเคสแบบนี้ผมจะตัดค่าที่สูงมากจนผิดปกติออก เพื่อทำเราสามารถวิเคราะห์ได้ใกล้เคียงค่าความเป็นจริงมากที่สุด
ซึ่ง Mean Median ก็นับเป็นวิธีการทางสถิติรูปแบบหนึ่ง ซึ่งในความเป็นจริงแล้วสถิตินั้นมีเครื่องมือแนวคิดมากมายให้เราหยิบเอาไปใช้ หนังสือเล่มนี้จึงทำให้คนที่สนใจเรื่องดาต้า คนที่ไม่ได้เรียนสถิติมาพอเข้าใจว่าเราควรต้องเลือกใช้เครื่องมือทางสถิติชิ้นใดครับ
เมื่อใช้ดาต้ากับสถิติ ก็ทำให้เราสามารถจับคนโกงข้อสอบได้ง่ายขึ้น ด้วยการหารูปแบบคนที่มีการทำข้อสอบข้อที่ผิดเหมือนๆ กัน เพราะข้อถูกมันมีข้อเดียวซึ่งการถูกเหมือนกันไม่ใช่เรื่องแปลกเท่าไหร่ แต่กับการตอบผิดที่มีตัวเลือกมากกว่า ถ้ายังสามารถติดผิดเหมือนกันได้จนกลายเป็น Pattern ก็จะเป็น Signal ที่บอกให้รู้ว่ามีความผิดปกติในคนกลุ่มที่ตอบผิดเหมือนกันอย่างน่าสงสัย ทำให้ทีมสืบสวนสอบสวนสามารถเจอจุดที่น่าสงสัยและเข้าไปแก้ไขปัญหาได้เร็วขึ้น
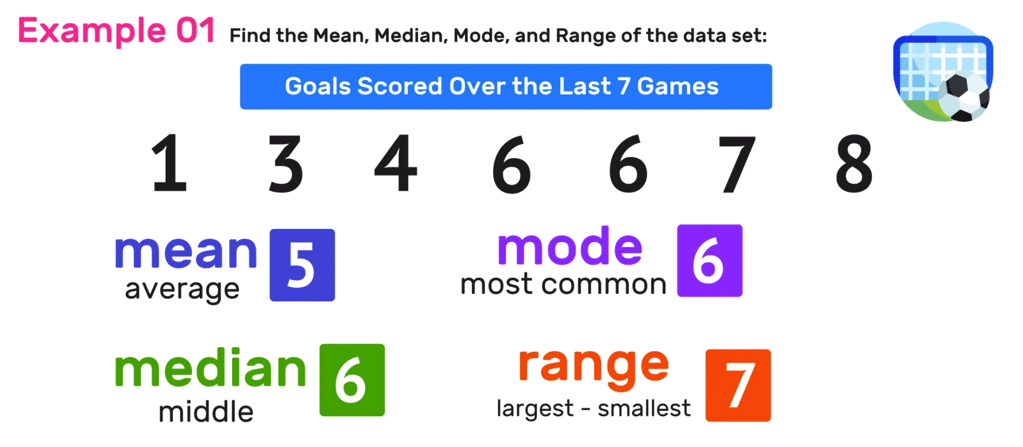
Standard Deviation ส่วนเบี่ยงเบนมาตรฐาน
คำนี้ผมเจอใน Looker Studio มานาน แต่ไม่เคยเข้าใจอย่างถ่องแท้ว่ามันคืออะไร จนกระทั่งหนังสือ Naked Statistics สถิติฉบับเซ็กซี่เล่มนี้ทำให้เข้าใจเป็นครั้งแรกว่า มันคือส่วนเบี่ยงเบนมาตรฐาน มันคือการที่ค่าต่างๆ ของชุดข้อมูลนั้นกระจายออกจากศูนย์กลางไป
เช่น สมมติค่าเฉลี่ยรายได้ของคนไทยอยู่ที่ปีละ 150,000 บาท ใครที่มีรายได้อยู่ที่ปีละ 120,000 บาท อาจรู้สึกว่าตัวเองมีรายได้ต่ำกว่าค่าเฉลี่ย ซึ่งรู้สึกน่าอับอาย แต่ยังมีอีกค่าที่เราต้องรู้ นั่นก็คือ Standard Deviation หรือส่วนเบี่ยงเบนมาตรฐาน เช่น ส่วนเบี่ยงเบนมาตรฐานของค่าเฉลี่ยรายได้คนไทยอยู่ที่ 40,000 นั่นหมายความว่ารายได้โดยส่วนใหญ่ของคนไทยอยู่ตั้งแต่ 110,000-190,000 บาท พอเห็นภาพใช่ไหมครับ ถ้ายังนึกภาพไม่ออก ก็ดูจากรูปประกอบด้านล่างได้
หนังสือเล่มนี้ยกตัวอย่างของการจอดรถตามห้างสรรพสินค้า รถมักจะจอดจุดที่ใกล้กับประตูทางเข้าที่สุด จากนั้นก็ค่อยๆ กระจายตัวออกไปทั้งทางด้านข้างและด้านลึก พอนึกภาพออกใช่ไหมครับ นั่นแหละคือ Standard Deviation หรือส่วนเบี่ยงเบนมาตรฐาน ดังนั้นจะดูแค่ค่าเฉลี่ย หรือค่ากลางของชุดข้อมูลนั้นไม่ได้ ต้องดูค่าสถิติตัวนี้ด้วย แล้วคุณจะเห็นการกระจายตัวของชุดข้อมูลที่มีอยู่ จะได้รู้ว่าตกลงข้อมูลนั้นมีการกระจุกตัวหนาแน่น หรือกระจายตัวออกไปมากจนค่าเฉลี่ยอาจไม่ค่อยน่านำมาใช้งานเท่าไหร่
สถิติบิดได้
เรื่องนี้ก็ต้องระวังให้ดี บางทีเราอาจถูกตัวเลขหลอกโดยไม่ตั้งใจ อย่างการขึ้นภาษีจาก 3% เป็น 5% สามารถบิดดาต้าได้สองมุม
- เพิ่มขึ้นแค่ 2% จาก 3 ไป 5
- เพิ่มขึ้นจากเดิม 67% เพราะเพิ่ม 2 จาก 3
แม้ผลลัพธ์สุดท้ายจะเท่ากัน แต่วิธีการใช้หลักสถิตินำเสนอกลับให้ความรู้สึกที่ต่างกัน แบบแรกรู้สึกน้อยมาก จนแทบไม่รู้สึกต่าง แบบหลังรู้สึกมหาศาล แบบโลกแทบแตกแผ่นดินทลาย
ดังนั้นก่อนจะจะเชื่อค่าเปอร์เซนต์ใด จงทำความเข้าใจข้อมูลให้ดี จะได้รู้ว่าเขาต้องการปั่นหัวเราไปทางไหนนะครับ
สองบริษัทเครือข่ายโทรศัพท์มือถือของอเมริกาอย่าง AT&T กับ Verizon เองก็พยายามให้บริการลูกค้าดีที่สุด
Verizon บอกว่าตัวเองครอบคลุมพื้นที่มากกว่า แต่ AT&T กลับบอกว่าเครือข่ายของเขาครอบคลุมคนอเมริกา 97% ตัวเลขฟังดูไม่ต่าง อ่านเผินๆ ดูคล้ายกัน แต่ความจริงแล้วต่างกันมหาศาลนะครับ
เพราะประเทศอเมริกานั้นกว้างใหญ่ไพศาลมาก การจะกระจายเสาสัญญาให้ครอบคลุมทุกพื้นที่นั้นต้องใช้การลงทุนมหาศาล
Verizon เลยต้องลงทุนตั้งเสาสัญญาณให้ครอบคลุมพื้นที่ทั่วประเทศอเมริกา แต่กับ AT&T นั้นมีกลยุทธ์ที่ต่าง เขาบอกว่าสัญญาณเขาครอบคลุมคนอเมริกา 97% ซึ่งเป็นข้อมูลคนละมิติกับพื้นที่อย่างสิ้นเชิง
เพราะผู้คนมักกระจุกตัวกันอยู่ตามเมืองเป็นหลัก นั่นหมายความว่าสัญญาณที่ครอบคลุมคนอเมริกา 97% อาจครอบคลุมพื้นที่แผ่นดินจริงๆ แค่ 50-80% ก็ได้
เพราะหลายพื้นที่ในอเมริกานั้นรกร้าง จึงเป็นกลยุทธ์ธุรกิจที่ทำให้ตัวเองมีต้นทุนน้อยที่สุด แต่สามารถครอบคลุมกลุ่มลูกค้าได้มากที่สุด
ดังนั้นก่อนจะเชื่อดาต้าใด จงทำความเข้าใจดาต้านั้นให้ดีด้วยนะครับ ว่าถูกบิดหรือปรุงแต่งมาอย่างไรบ้าง
Strategy from Statistics แคมเปญการตลาดเบียร์รอง ที่ใช้หลักสถิติ เอาชนะเบียร์พรีเมียม
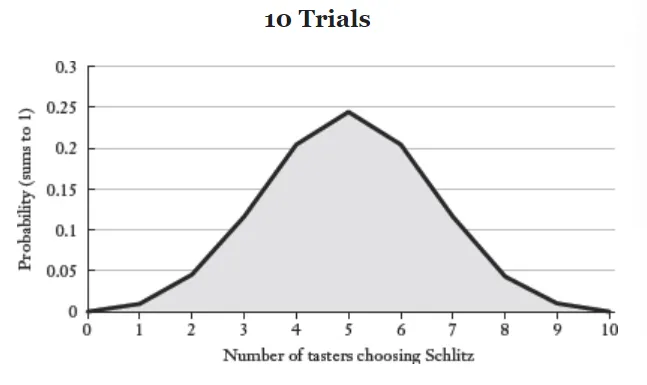
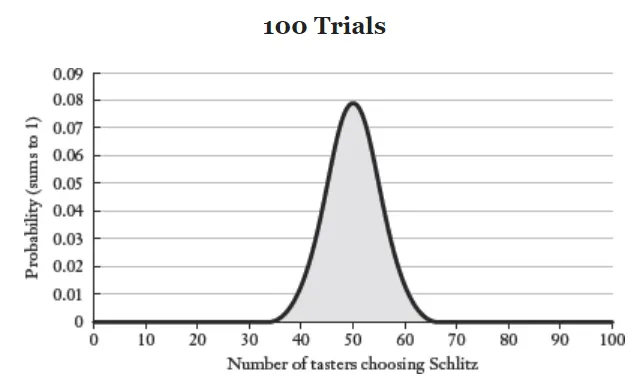
เมื่อเบียร์รองบ่อนอย่าง Schlitz พยายามจะเอาชนะเบียร์ที่พรีเมียมกว่ารายหนึ่ง พวกเขาเลยจัดแคมเปญการตลาด Blind test ให้เหล่านักดื่มเบียร์ได้ลองดื่มดูจริงๆ แล้วจากนั้นถามคนดื่มว่าแยกออกไหมว่าแก้วไหนคือเบียร์ที่พรีเมียมกว่า
ผลลัพธ์ที่ได้คือคนกว่าครึ่งแยกไม่ออก ก็เลยถูกตบเข้าสู่กลยุทธ์แคมเปญการตลาดแบบฉลาดใช้หลักสถิติคือ “ถ้าคุณแยกไม่ออก ก็ไม่ควรจ่ายแพงกว่า ดื่ม Schlitz ก็ได้”
ซึ่งในความเป็นจริงแล้วนี่คือหลักสถิติที่เรียกว่า “การถอยกลับคืนสู่ค่าเฉลี่ย” นั่นหมายความว่าถ้ามีกลุ่มตัวอย่างมาทดสอบน้อย ค่าที่ได้อาจหนักไปทางใดทางหนึ่ง แต่ถ้ายิ่งทดสอบด้วยกลุ่มตัวอย่างมากเท่าไหร่ ค่าที่ได้ยิ่งเข้าใกล้ค่าเฉลี่ยมากเท่านั้น
นี่คือหลักการเดียวกันกับที่บ่อนการพนันทั่วโลกใช้ ที่เขาทำกำไรจากโอกาสที่มากกว่าคุณแค่เล็กน้อย อาจจะแค่ 1% เท่านั้น แต่ถ้ามีคนเข้ามาเล่นเป็นหมื่นๆ แสนๆ ล้านๆ หนึ่งเปอร์เซนต์นั้นก็จะกลายเป็นกำไรของบ่อนในที่สุด
นั่นบอกให้รู้ว่าอย่าพยายามเล่นกับบ่อนเยอะครั้ง เล่นนานทีครั้งแล้วคุณจะมีโอกาสชนะมากกว่าครับ
เราควรเสียเงินจ่ายค่าประกันหรือไม่ ประเมินได้ด้วยหลักสถิติ
ธุรกิจประกันมีไว้เพื่อคุ้มครองความเสี่ยง ไม่ว่าจะสุขภาพหรืออุบัติเหตุ แต่รู้ไหมครับว่าในความเป็นจริงแล้วบริษัทประกันมักจะเก็บค่าเบี้ยให้สูงกว่าค่าความเสี่ยงจริงอยู่แล้ว ดังนั้นหนังสือเล่มนี้จึงแนะนำง่ายๆ ว่าถ้าเราสามารถจ่ายค่าเสียหายทั้งหมดด้วยตัวเองได้ ก็ไม่จำเป็นต้องเสียเงินจ่ายค่าเบี้ยประกันที่แพงเกินจริงครับ
ถ้าเป็นพวกค่าประกันเครื่องใช้ไฟฟ้า พรินท์เตอร์ คอมพิวเตอร์ มือถือ หรือใดๆ ถ้าเราสามารถจ่ายค่าเสียหายทั้งหมดที่เกิดขึ้นด้วยตัวเองได้ คำแนะนำสั้นๆ คือไม่จำเป็นต้องเสียเงินทำประกันแต่อย่างไร ให้ทำประกันแต่ค่าเสียหายที่เราไม่สามารถจ่ายด้วยตัวเองไหว
เช่น ถ้ารถเสียหายหรือพังทั้งคันเราไม่สามารถรับผิดชอบได้ ทำประกันจะคุ้มกว่า แต่ถ้าเรามีเงินมากพอจะดูแลความเสียหายตรงนั้น ก็อย่าเสียเงินทำประกันเลยครับ
จาก Data & Stat เราสามารถส่งตำรวจไปหยุดการเกิดอาชญากรรมล่วงหน้าได้
คิดถึงภาพยนต์เรื่อง Minority report เลยครับ ที่เราสามารถคาดการณ์ได้ล่วงหน้าว่าจะเกิดการก่อเหตุร้ายหรืออาชญากรรมตรงไหน แต่ในปัจจุบันนี้ไม่ได้แม่นยำขนาดว่าใครจะทำอะไรขนาดนั้นนะครับ แต่ก็พอจะคาดการณ์ได้ว่าถ้ามีคนแบบไหนมารวมตัวกันเยอะๆ ตรงนั้นก็มีโอกาสจะเกิดอาชญากรรมได้มากกว่าปกติ จึงส่งเจ้าหน้าที่ไปดูแลพื้นที่นั้นล่วงหน้า เพื่อลดโอกาสเกิดอาชญากรรมตั้งแต่เนิ่นๆ น่าสนใจไหมครับ
บริษัทบัตรเครดิต FinTech ต่างๆ รู้จักตัวตนเราดีกว่าตัวเราเองจาก Data & Stat
สุดท้ายเรื่องนี้น่าสนใจครับ ที่เป็นเวลาหลายสิบปีมาแล้วที่บรรดาบริษัทบัตรเครดิตต่างๆ ที่มีข้อมูลการจับจ่ายใช้สอยเงินของเรานั้นจะรู้ว่าเราน่าจะเป็นคนที่เบี้ยวหนี้ในอนาคตมากน้อยแค่ไหน โดยดูจากแค่พฤติกรรมการใช้เงิน ดูจากสิ่งที่เราซื้อเท่านั้นเอง
เช่น คนที่เข้าร้านเหล้า มีแนวโน้มจะเบี้ยวหนี้มากกว่าคนที่ไปหาหมอฟันถึง 4 เท่า รู้แบบนี้แล้วพึงระวังไว้ ว่าเรากำลังซื้ออะไรที่ทำให้บริษัทการเงินประเมินว่าเราเป็นคนที่น่าจะมีวินัยทางการเงินที่ไม่ดีหรือเปล่านะครับ
อ่านแล้วเล่า เล่มที่ 6 ของปี 2023

นี่คือหนังสือที่แนะนำให้นักการตลาดสายดาต้าได้อ่าน เพราะเรื่องดาต้ากับสถิตินั้นเกี่ยวกันอย่างมากจนแยกจากกันไม่ได้ ถ้าเราทำดาต้าโดยไม่รู้เครื่องมือทางสถิติ จะเป็นอะไรที่เสียเปรียบมาก แต่ถ้าเราเข้าใจเครื่องมือทางสถิติต่างๆ การทำดาต้าของเราจะไปได้ไวและไกลกว่าเดิมมากจริงๆ ครับ
สรุปหนังสือ Naked Statistics สถิติฉบับเซ็กซี่
Stripping the Dread from the Data
Charles Wheelan เขียน
ณัฏฐพรรณ เรืองศิรินุสรณ์ และ กฤดิกร เผดิมเกื้อกูลพงศ์ แปล
สำนักพิมพ์ Bookscape
อ่านสรุปหนังสือแนวนี้ในอ่านแล้วเล่าต่อ > https://www.summaread.net/category/big-data/
สั่งซื้อออนไลน์ > https://www.naiin.com/product/detail/523754