
สรุปหนังสือ Fundamental of Deep Learning in Practice จากสำนักพิมพ์ Infopress ที่แต่งโดย อ. ดร. ณัฐโชติ พรหมฤทธิ์ และ อ. ดร. สัจจาภรณ์ ไวจรรยา เล่มนี้ทำให้เห็นภาพรวมเชิงลึกพร้อมของโลก Data ที่กำลังขับเคลื่อนโลกทั้งใบโดยที่เราส่วนใหญ่ไม่รู้ตัว แม้หนังสือเล่มนี้จะเต็มไปด้วย Practice มากมาย ที่เชื่อว่าสายปฏิบัติต้องชอบ เพราะสามารถอ่านแล้วทำตามได้ทีละ Step by Step เพียงแต่ผมเป็นสายการตลาดและธุรกิจที่อาจไม่ได้ใช้ประโยชน์จากส่วนนั้นเท่าไหร่นัก (พูดตรงๆ คือไม่ได้ทำตามเลยสักบรรทัด) แต่เนื้อหาภาพรวมทั้งหมดก็ทำให้เข้าใจว่า Deep Learning คืออะไร ต่างจาก Programming แบบเดิมอย่างไร และต่างอย่างไรกับ Machine Learning บ้าง
ที่สำคัญกว่านั้นคือโมเดลของ Machine Learning หรือ Deep Learning มีกี่แบบ แล้วการ Predict มีกี่แบบ ซึ่งตรงนี้ดีมากครับ แม้จะพอรู้และเคยเขียนมาบ้าง แต่พอได้อ่านจากเล่มนี้ก็ทำให้เข้าใจและเชื่อมโยงได้ดีขึ้น ว่าแต่ละส่วนเกี่ยวกันอย่างไร ดังนั้นผมจะขอสรุปแค่บางส่วนในหนังสือที่ผมเข้าใจและสนใจให้กับเพื่อนๆ นักการตลาดไปจนถึงคนที่ไม่ใช่สาย Dev ได้รู้กันนะครับ
1. Traditional Programming ต่างกับ Machine Learning อย่างไร
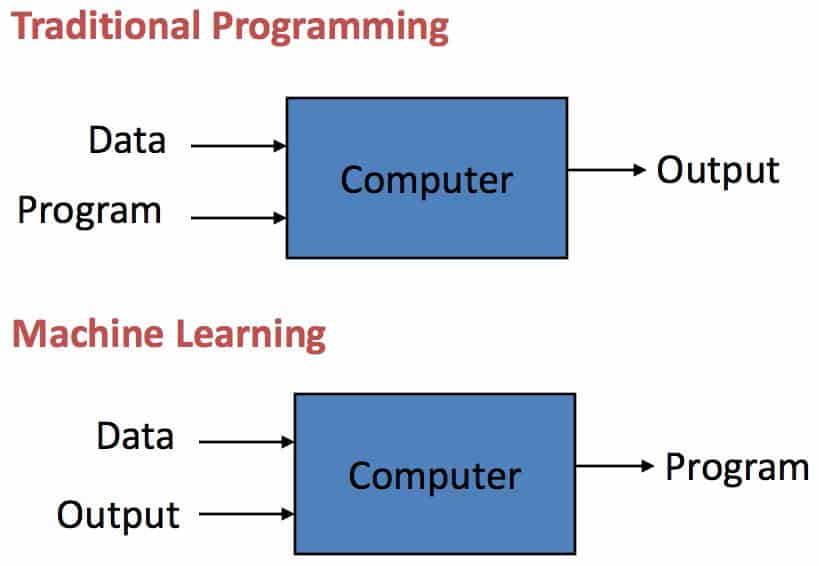
ภาพหน้านี้ทำให้ผมสิ้นสงสัย เพราะทำให้เห็นภาพชัดเจนว่าการเขียนโปรแกรมแบบเดิมต่างกับการทำ Machine Learning อย่างไร ถ้าให้สรุปสั้นๆ คือการเขียนโปรแกรมแบบเดิมคือการกำหนดค่าหรือกติกาขั้นมาชัดเจน ว่าจะให้คอมพิวเตอร์ทำงานอย่างไร ให้โปรแกรมทำงานแบบไหน จากนั้นก็ปล่อยให้มันทำงานตาม Algorithm ที่เรากำหนดไว้
แตการทำ Machine Learning คือการป้อนข้อมูลเข้าไป กับป้อนผลลัพธ์ที่ต้องการเข้าไป ตัวอย่างที่ชอบยกกันบ่อยๆ คือทำ Machine Learning ให้แยกภาพหมากับแมวให้ออก Data set ชุดแรกเป็นภาพหมาเยอะๆ หลายๆ แบบ แล้วปล่อยให้ Machine ไป Learning เอาเองว่าหมามีองค์ประกอบแบบไหนอย่างไรบ้าง แล้วก็ป้อนภาพแมวเข้าไปให้มันเรียนรู้เอา จากนั้นก็ลองทดสอบว่า Machine ของเราฉลาดพอจะทำงานแยกภาพหมากับแมวด้วยตัวเองได้ดีพอแล้วหรือยัง
ถ้ายังก็เทรนเพิ่ม ถ้าดีแล้วก็เอามาทำงานเลย จะเห็นว่าการทำ Machine Learning ขึ้นอยู่กับคุณภาพของ Data ที่ป้อนเข้าไปด้วย ยิ่งป้อนเข้าไปเยอะเท่าไหร่มันก็ยิ่งเรียนรู้ที่จะจำแนกได้ดีเท่านั้น
ลองดูคลิปวิดีโอนี้ประกอบก็ได้ครับ ผมใช้ในการสอนบ่อย
จากนั้นก็นำมาสู่คำถามถัดไปคือ Machine Learning มีกี่แบบ?
3 ประเภท Machine Learning
หนังสือ Fundamental of Deep Learning in Practice เล่มนี้ทำให้ผมเข้าใจสิ่งที่เคยเข้าใจแต่กระจัดกระจายว่า Supervised Learning Unsupervised Learning และ Reinforcement Learning คือประเภทของการทำ Machine Learning

ลองมาทำความรู้จัก Machine Learning ทั้ง 3 ประเภทแบบคร่าวๆ กันนะครับว่าคอนเซปมันเป็นอย่างไร ต่างกันอย่างไร จะได้เอาไปประยุกต์ใช้หรือบอกทีม Data ได้ถูก
1. Supervised Learning สอนให้เรียนรู้
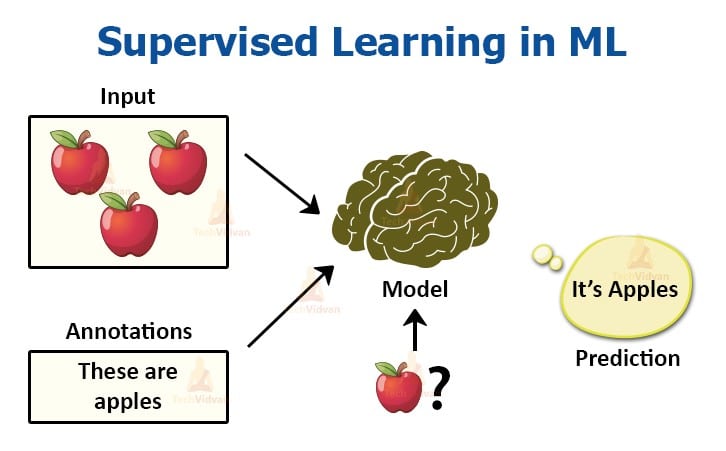
สอนให้เรียนรู้ว่าอะไรเป็นอะไร จากภาพตัวอย่างจะเห็นว่า Supervised Learning คือการสอนให้ Machine ซึ่งก็คือโปรแกรมเรียนรู้ผ่านชุดข้อมูลว่าสิ่งนี้คืออะไร เมื่อเรียนรู้มากพอถึงจุดหนึ่งมันก็จะเรียนรู้ด้วยตัวเองว่าข้อมูลใหม่ที่ได้รับมาใช่สิ่งนั้นหรือใหม่
แต่ทั้งนี้ทั้งนั้น Supervised Learning ต้องอาศัยคนสอน ซึ่งอาจมี bias การสอนซ่อนอยู่โดยไม่รู้ตัว อย่างที่เห็นในหลายๆ เคส ตปท เช่น ชนกลุ่มน้อยในสหรัฐ หรือคนผิวดำ ถูก Algorithm Bias ว่ามีแนวโน้มจะกู้เงินได้น้อยกว่า ดอกสูงกว่า หรือก่ออาชญากรรมมากกว่าคนผิวขาวครับ
2. Unsupervised Learning ปล่อยให้เรียนรู้เอง

การทำ Marchine Learning แบบที่สองคือ Unsupervised Learning ซึ่งก็ตรงกันข้ามกับแบบแรก คือปล่อยให้โปรแกรมเรียนรู้ด้วยตัวเองว่าอะไรเป็นอะไร จากภาพตัวอย่างคือป้อนชุดข้อมูลผลไม้ที่หลากหลายเข้าไป แล้วก็รอดูว่าโปรแกรมจะจัดกลุ่มผลไม้ออกมาเป็นแบบไหน อาจจะเลือกจากขนาด สี ทรง หรืออื่นๆ เท่าที่มี Data บอกไว้ ดังนั้นยิ่งมีข้อมูลละเอียดเท่าไหร่ ก็น่าจะยิ่งทำให้การทำ Machine Learning แบบ Unsupervised Learning มีประสิทธิภาพมากขึ้นเท่านั้น
3. Reinforcement Learning เรียนรู้ผ่านรางวัล

Machine Learning ประเภท 3 คือการเรียนรู้แบบ Reinforcement Learning คือการเรียนรู้แบบมีรางวัลตอบแทน ตัวอย่างคือ Alpha Go สามารถเรียนรู้การเล่นโกะด้วยตัวเองได้ ด้วยการรู้ว่าทำแบบไหนแล้วจะได้รางวัลตอบแทน นั่นก็คือการชนะ และแบบไหนจะแพ้ โดยที่ไม่ต้องสอนกติกาให้ Alpho Go รู้เลยว่าหมากล้อมจะเล่นอย่างไร เพราะเมื่อเป็น Machine ก็สามารถที่จะเรียนรู้การเล่นเป็นล้านกระดานภายในระยะเวลาสั้นๆ

ดังนั้นยิ่งมีรอบการป้อน Feedback ที่เร็วเท่าไหร่ ก็จะยิ่งทำให้ AI หรือ Machine ของเราฉลาดมากขึ้นเท่านั้น
จาก 3 ประเภทของ Machine Learning แล้วอีกเรื่องที่น่าสนใจที่นักการตลาดและคนทำธุรกิจทุกคนควรรู้ต่อไปคือ การ Predict มีกี่แบบ
3 ประเภทของการ Predict จาก Machine Learning
แน่นอนว่าการทำ Data Analytics หรือการทำ Data Project ทั้งหมดก็เพื่อพยายามคาดการณ์สิ่งที่น่าจะเกิดขึ้นในอนาคตให้ได้แม่นยำที่สุด เพราะโลกธุรกิจวันนี้แข่งขันกันที่ความสามารถในการ Predict เช่น ลูกค้าคนไหนน่าจะกำลังอยากซื้ออะไร หรือลูกค้าคนไหนกำลังจะเลิกเป็นลูกค้าเรา หรือสินค้าไหนน่าจะขายดีช่วงไหน จะได้สต็อกไว้ล่วงหน้า และสินค้าไหนที่ไม่น่าจะขายได้ตอนไหนบ้าง จะได้ปรับสต็อกและคลังสินค้าให้สมดุล
ส่วนรูปแบบของการ Predict มาทั้งหมด 3 แบบดังนี้ครับ
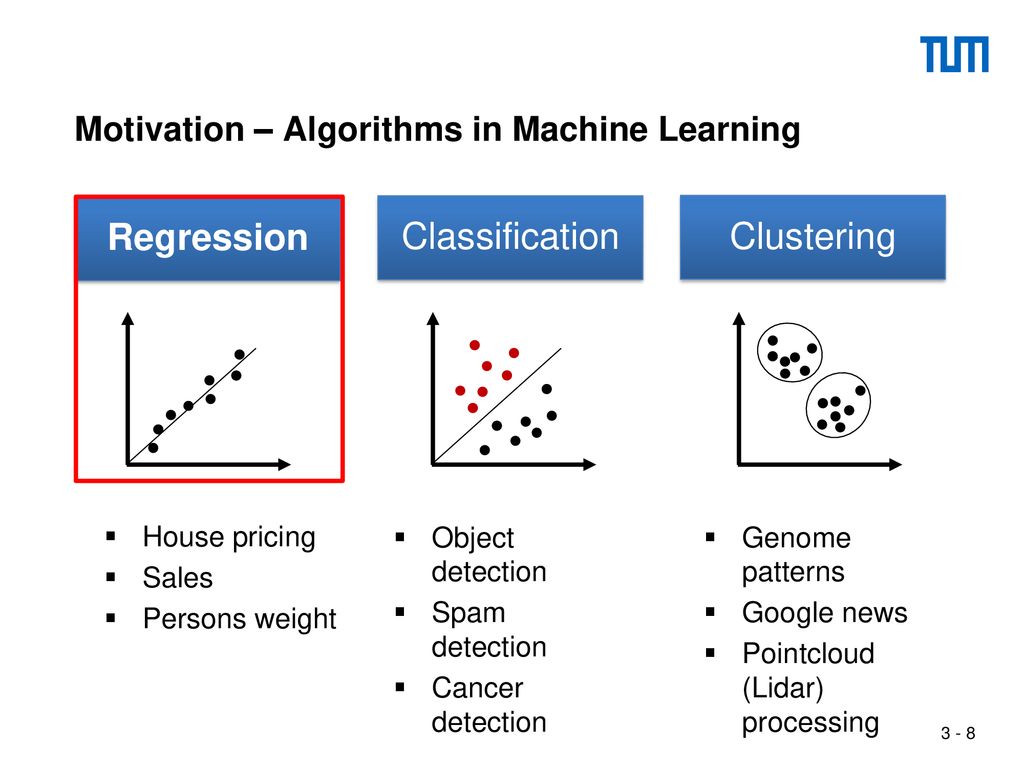
- Regression การวิเคราะห์หาแนวโน้ม แล้วคาดการณ์ถึงความน่าจะเป็นในอนาคต เช่น สินค้าบางอย่างขายดีเมื่อฝนตก หรือพายุหิมะมา ก็ใช้คาดการณ์ในการเตรียมสต็อกสินค้า ไปจนถึงวิธีทำการตลาดล่วงหน้าในครั้งถัดไปก่อนฝนตกหรือหิมะเข้า
- Classification การวิเคราะห์เพื่อคาดการณ์การแบ่งแยกในอนาคต เช่น ส้ม กับ มะนาว ถ้าเราป้อนข้อมูลเข้าไปมากพอให้ Machine Learning เรียนรู้ว่า ส้ม กับ มะนาว นั้นแบ่งกันด้วยอะไรบ้าง ทรงกลม เหมือนกัน แบ่งไม่ได้ ขนาด มะนาวเล็กกว่าส้มเป็นส่วนใหญ่ ยกเว้นบางสายพันธ์ที่ส้มผลเล็ก ส่วนมะนาวผลใหญ่มาก แบ่งด้วยสี มะนาวส่วนใหญ่สีออกเขียวจัด ส้มออกสีส้ม เมื่อเทรนด้วย Data ที่มากพอการคาดการณ์เมื่อเห็นผลส้มกับมะนาวปนกัน Machine ก็จะช่วยเบางานเราในการคัดผลไม้ออกไปได้ดีกว่าใช้แค่คนอย่างเดียว
- Clustering การวิเคราะห์เพื่อแบ่งกลุ่มอัตโนมัติ เช่น การทำ Segmentation of Customer หรือการแบ่งกลุ่มลูกค้าออกมาเป็นกลุ่มต่างๆ ให้ได้ละเอียดและมีประสิทธิภาพในการทำการตลาดมากที่สุด เช่น case study ของห้าง Target ที่แบ่งกลุ่มคนท้องออกมาจากกลุ่มลูกค้าทั้งหมดที่มี เพื่อต้องการจะทำการตลาดแบบ Personalized Marketing ในระดับ Segmentation เพราะรู้แล้วว่าลูกค้ากลุ่มนี้มีพฤติกรรมการซื้อในระยะยาวที่ทำกำไรให้ธุรกิจได้ดีกว่าลูกค้า Segments อื่น
สามสิ่งนี้ผมก็พอรู้มาบ้าง แต่ไม่เคยรู้วิธีการจัดหมวดหมู่และการใช้งานแบบนี้มาก่อน ต้องยอมรับว่าหนังสือ Fundamental of Deep Learning in Practice เล่มนี้ช่วยยกระดับความรู้เรื่อง Data ผมขึ้นไปอีกขั้นจริงๆ
จากนั้นหนังสือเล่มนี้ก็พาผมไปรู้อีกเรื่องหนึ่งที่ดีมาก เพราะผมรู้ว่าเวลาเราทำ Data ต้องทำสิ่งนี้ แต่ผมไม่เคยรู้ว่าสิ่งนี้เรียกว่าอะไร นั่นก็คือ
Feature Engineering สกัดข้อมูลในดาต้า
คำว่า Data is the new oil นั้นถูกใช้กันมายาวนาน แต่อย่างหนึ่งที่หลายคนอาจไม่รู้คือ Data ไม่สามารถใช้งานได้ทันที แต่ต้องนำมาสกัดเพื่อให้นำไปใช้งานต่อได้ เฉกเช่นน้ำมันดิบขุดมาแล้วยังใช้เลยไม่ได้ แต่ต้องผ่านการสกัดหลายขั้นตอน แล้วแต่ละขั้นที่ทำการสกัดก็ได้ผลิตผลคนละแบบ

เช่น ข้อมูลของสี จากซ้ายคือ Raw Data เราต้องเอามาผ่านการทำ Feature Engineering เพื่อทำให้ Machine Learning ได้ง่ายขึ้นเพื่อผลลัพธ์ที่ดีขึ้น
นี่คือสิ่งที่นักการตลาดและคนทำธุรกิจต้องรู้ เพราะหลายครั้งดาต้าที่เรามีอาจมี Insight ซ่อนอยู่มากมาย และถ้าเราทำ Feature Engineering ดีๆ เราก็จะสามารถเห็นอะไรได้อีกเยอะที่เราอาจไม่คาดคิดมาก่อน
Data Binning เทคนิคการทำ Visualization ที่นักการตลาดต้องรู้
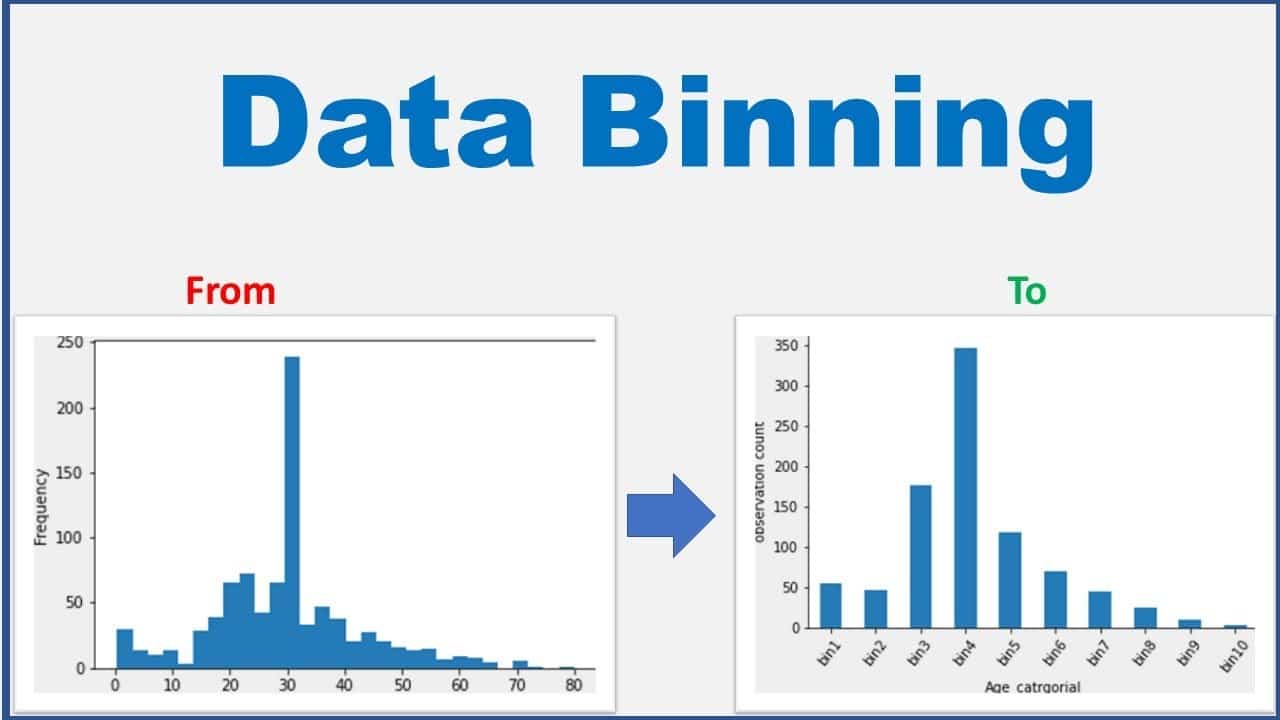
นี่ก็เป็นอีกหัวข้อที่มีประโยชน์มากสำหรับคนที่ไม่ใช่สาย Technical จ๋า แต่สามารถเอามาทำจริงได้ไม่ยากไป เทคนิคการทำ Data Binning อันนี้แต่เดิมผมไม่รู้ว่าเรียกว่าอะไร มันคือการจัดหมวดหมู่ข้อมูลเพื่อทำให้ง่ายต่อการ Analytics ผ่านการทำ Data Visualization ให้เห็นภาพรวมได้ชัดขึ้น เหมือนที่ผมเคยใช้วิเคราะห์หาว่ากลุ่มผู้สมัครเรียนกับการตลาดวันละตอนเวลาทำแต่ละคอร์สออกมาเป็นใคร อายุเท่าไหร่
จากที่เคยคิดภาพไว้ว่าน่าจะเป็น First Jobber ที่อายุประมาณ 2x หรือ 3x ต้นๆ กลายเป็นว่าเอาเข้าจริงอยู่ที่ 3x-4x เป็นส่วนใหญ่เกินครึ่งครับ
สรุปได้ว่าเทคนิค Data Binning คือการแบ่ง Data ออกตามช่วงที่กำหนด
Collaborative Filtering
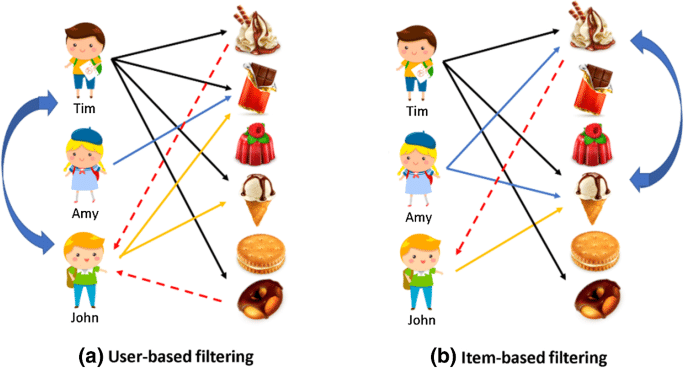
เทคนิคสุดท้ายที่น่าสนใจและสำคัญต่อการตลาดกับธุรกิจคือ Collaborative Filtering มันคือการทำ Recommendation ที่เราใช้อยู่ในชีวิตประจำวันมานานจนอาจหลงลืมไป เช่น Netflix แนะนำหนังที่ถูกใจให้เราได้มากมายก็ด้วยเทคนิคนี้ครับ
เขาดูว่าคนที่ชอบดูหนังสไตล์คล้ายๆ กับเราชอบดูอะไรต่อ แล้วระบบก็แนะนำหนังนั้นให้กับคนที่ยังไม่เคยดู หรือตามเว็บไซต์ช้อปออนไลน์ทั้งหลายที่มีสินค้าแนะนำด้านล่าง มันไม่ได้แนะนำสุ่มสี่สุ่มห้าแบบเว็บสมัยก่อน แต่มันแนะนำจากประวัติการซื้อ การดู การค้นหาในอดีตของเรา เทียบกับกลุ่มลูกค้ามากมายที่มี แล้วคาดการณ์ว่าเราน่าจะอยากซื้ออะไรเป็นชิ้นถัดไป
ซึ่งเกณฑ์ในการ Filter ก็มีสองแบบ
- User-based filtering คนแบบเดียวกันชอบอะไร แล้วแนะนำแบบนั้นให้
- Item-based filtering สินค้าแบบนี้คนแบบไหนชอบซื้อ แล้วแนะนำสินค้านั้นให้กับคนที่ชอบซื้อของแบบนั้น
สรุปหนังสือ Fundamental of Deep Learning in Practive

ผมคิดว่าหนังสือเล่มนี้แม้จะเป็นเนื้อหาไปทาง Technical แบบจับมือทำลงมือตาม แต่ผมก็พบว่าบางหัวข้อ หลายประเด็นก็ยังเป็นประโยชน์กับคนที่ไม่ใช่สาย Dev อย่างผม นักการตลาดและคนทำธุรกิจควรรู้ไว้ ว่าวันนี้ Machine Learning หรือ Deep Learning คืออะไร ทำงานอย่างไร และทำงานแบบไหน เพราะในโลกที่ Driven ด้วย Data Everything เราจะบอกว่าไม่รู้เรื่องนี้ไม่ได้ครับ
สรุปหนังสือ เล่มที่ 1 ของปี 2022
สรุปหนัง Fundamental of Deep Learning in Practive
Best Practice Workshop Machine Learning, AI Capabilities และ AI Application
ทำความเข้าใจแนวคิด การพัฒนาโมเดล และการประยุกต์ใช้งาน ด้วยการเขียนโค้ด Python บน Jupyter Notebook โดยใช้ Library เช่น TensorFlow, Scikit-learn และ NumPy
ผู้แต่ง อ. ดร. ณัฐโชติ พรหมฤทธิ์ และ อ. ดร. สัจจาภรณ์ ไวจรรยา
สำนักพิมพ์ Infopress
อ่านสรุปหนังสือแนวนี้ในอ่านแล้วเล่าต่อ > https://www.summaread.net/category/big-data/
สั่งซื้อออนไลน์ > https://click.accesstrade.in.th/go/YL3g5Scv